
For years, a quiet bottleneck has choked security operations and slowed data-driven growth. The problem isn't that we lack data or tools. It's that our tools don't speak the same language. And in an era where speed is everything, the very engineers we need to build AI models and new products are stuck doing "data janitorial work." They parse logs, fix broken pipelines, and manually map fields. This hidden tax on engineering time is a direct drag on revenue and innovation.
A new category of solution is emerging to pay down this tax. By using AI to automate the heavy lifting of data standardization, these platforms offer what you might call an "intelligence upgrade" for data infrastructure. This article explores the growing chaos of security data, the rise of the Open Cybersecurity Schema Framework (OCSF) as a common language, and how AI-native data fabrics are finally making OCSF adoption practical.
The Universal Bottleneck: Security's "Tower of Babel"
The modern security stack is a patchwork of best-of-breed tools. There's antivirus, endpoint detection and response systems, firewalls, cloud platforms, and identity providers. Each one generates crucial telemetry. But each one speaks its own language. A source IP might be called src_ip in one system and source_address in another. In a third system, it could be buried somewhere inside a nested JSON object.
This fragmentation hits the business in three specific ways.
Revenue Blockage
New data sources, partners, or products require months of integration work. Every delay pushes revenue further out.
Talent Erosion
Your best engineers spend their days keeping brittle pipelines alive instead of building things that actually move the needle.
Escalating Risk
Inconsistent data means slower threat detection, messier investigations, and AI models you can't fully trust. The industry has needed a common language for years. That need led to the Open Cybersecurity Schema Framework, or OCSF.
OCSF: The Promise of a Common Language
OCSF is an open-source and vendor-agnostic standard that gives security telemetry a unified schema. Think of it as a universal translator for security data.
What it actually does for you
OCSF replaces countless custom parsers with a single, reliable schema. So when you write a detection rule for a suspicious login, it works the same whether the data comes from Microsoft Entra ID, Okta, or Ping Identity. The field actor.user.name is always actor.user.name. For analysts, this kills the need for mental translation between tools. For the business, it means your security data layer becomes portable and future-proof. You are no longer locked into any single vendor's schema.
A growing list of major players including AWS, Google, Microsoft, CrowdStrike, and Splunk have adopted OCSF. It's about as close to industry consensus as we've ever gotten.
The Implementation Gap: Why a Standard Isn't Enough
Having a standard is one thing. Actually using it at scale is another. The journey from raw logs to clean OCSF events is surprisingly complex. And the mapping work is still mostly manual, painfully repetitive, and easy to get wrong.
Here's where it gets tricky. This problem shows up even when the original log source is identical.
Imagine a security team using two different pipeline tools, say Cribl and Fluentd, to collect Windows Defender alerts. Both tools forward the same core alert, but they add different metadata. They use different field names. They wrap the data in unique structures. The result? Two different versions of the same alert land in your SIEM. Now an analyst has to either manually normalize everything coming in or write separate detection rules. One rule for severity_label and another for alert.severity. That's the integration tax at work, and it's happening inside your own walls.
The core challenges
● Mappings are brittle. Writing valid OCSF events often means complex code that's a nightmare to maintain over time.
● Maintenance never ends. Vendors tweak their log formats constantly. One small change breaks your hand-built mapping, and suddenly your team is back in firefighting mode.
This gap between the promise of OCSF and the grind of implementation is exactly what a new wave of AI-native tools aims to close.
The Intelligence Upgrade: AI-Native Data Fabrics
These new platforms are built to do more than just move data. They understand it. They transform it. And they use AI to automate the parts of OCSF mapping that burn the most engineering hours.
You can read about this stuff all day, but you don't really understand a tool until you use it. So I signed up for Fleak's platform to see if this "intelligence upgrade" was real or just marketing. I threw a mix of logs from my lab at it. Some were clean, some were messy. Then I just watched what happened.
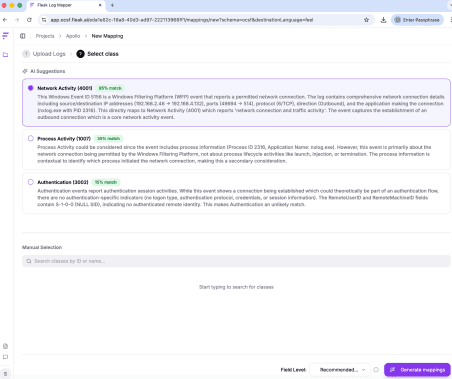
First, the uploaded logs were analyzed, and the top AI predictions are listed with confidence scores. The highest-ranked entry, with 95% confidence, is indeed a Network Activity Event classified under Network Activity, as shown in the following figure.
Next it generated a complete OCSF mapping as shown in the following figure:
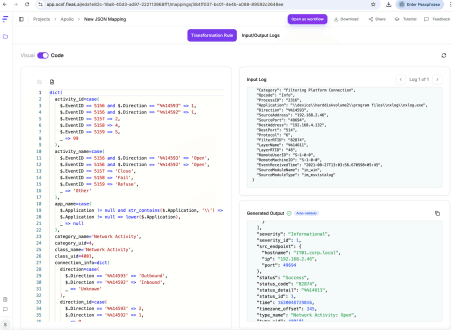
What would have taken me days to do manually was done in under an hour. The AI didn't just guess. It logically inferred field mappings, and the engine processed the streams without breaking a sweat. It became clear this wasn't just another parser. It was a system built to dismantle the integration tax at scale.
Once these mappings are validated, they can be deployed using ZephFlow, Fleak's open-source data processing framework. But the real magic is in the mapping layer. That's where the heavy lifting happens.
What stood out after spending time with the platform
● Mapping that doesn't require a PhD. Instead of writing parsers by hand, the system analyzes sample logs and generates transformation logic for you. Setup goes from months to weeks or hours.
● Pipelines that fix themselves. Schema drift is a fact of life in security. When it happens, this system spots it, figures out what changed, and suggests a fix. You're no longer waking up an engineer at 2 a.m. because a pipeline died.
● Run anywhere. The configurations aren't tied to one engine. You can deploy them on Spark, Flink, or ZephFlow itself. It fits into whatever infrastructure you already have.
The value proposition is that it reduces the integration tax by orders of magnitude. And that's exactly what the industry needs.
Case in Point: Quantifying the Impact
So what does this actually mean for a business? Take that Windows Defender example from earlier. With manual normalization, adding that new data source could take months of engineering time. With an AI-native fabric, it becomes a matter of days.
One global security platform I looked at cut their onboarding time from six months to one week. That meant their engineers stopped doing plumbing and started building things that mattered. And when you can launch new products and partnerships that fast, data stops being a bottleneck and starts being a growth engine.
Conclusion: A Necessary Evolution
Security teams are drowning in data but starving for insight. OCSF gives us a common language, but adoption has been slow because the translation work is so painful. AI-native data fabrics finally automate that pain away.
This isn't just about saving engineering hours. It's about what those engineers can do instead. They can build better detection logic. Train AI models. Launch products that grow the business. When you stop wrestling with data and start using it, security transforms from a cost center into a strategic advantage.
For any organization feeling the drag of the integration tax, the fix is here. The intelligence upgrade for your data pipeline isn't some future promise. It's something you can run in your own environment today.