Data overload and blind spots
Raw, unqualified data flows into your AI applications and data stores. Your models reason over everything equally — and get everything equally wrong.
Fleak is the AI infrastructure layer between your data and your AI applications — normalized, filtered, governed, delivered in real time.
TRUSTED BY

Raw, unqualified data flows into your AI applications and data stores. Your models reason over everything equally — and get everything equally wrong.
Every new source takes months to onboard. Every schema change breaks something. Your data engineering team never escapes maintenance mode.
You can control costs or maintain coverage — raw, unqualified data forces you to choose. Most teams quietly choose costs, and quietly accept the blind spots that follow.

Fleak's AI evaluates every incoming data point against what your downstream applications need — then routes it accordingly. What has real-time value moves fast. What has compliance value goes to long-term storage. What has no value goes nowhere.

Schema changed upstream? Fleak detects it, generates a new config, and redeploys — automatically. Human review optional.

Fine-grained access control enforced at the data layer. Every transformation logged. Full audit trail included.
→ SOC 2 TYPE II · FULL AUDIT TRAIL
6mo → 1wk
Time to first source live
vs. traditional pipeline development
90%
Integration cost reduction
vs. traditional pipeline development
50%
Storage cost reduction
from deduplication at ingestion
40%
LLM token cost savings
from normalized, deduplicated inputs
Millions
Events per second, Real-time
zero storage required
3 Minutes
Avg. self-heal time
when schema drift is detected
Cloud, OT, endpoints, APIs, databases — if it emits data, Fleak connects to it. No custom connectors.
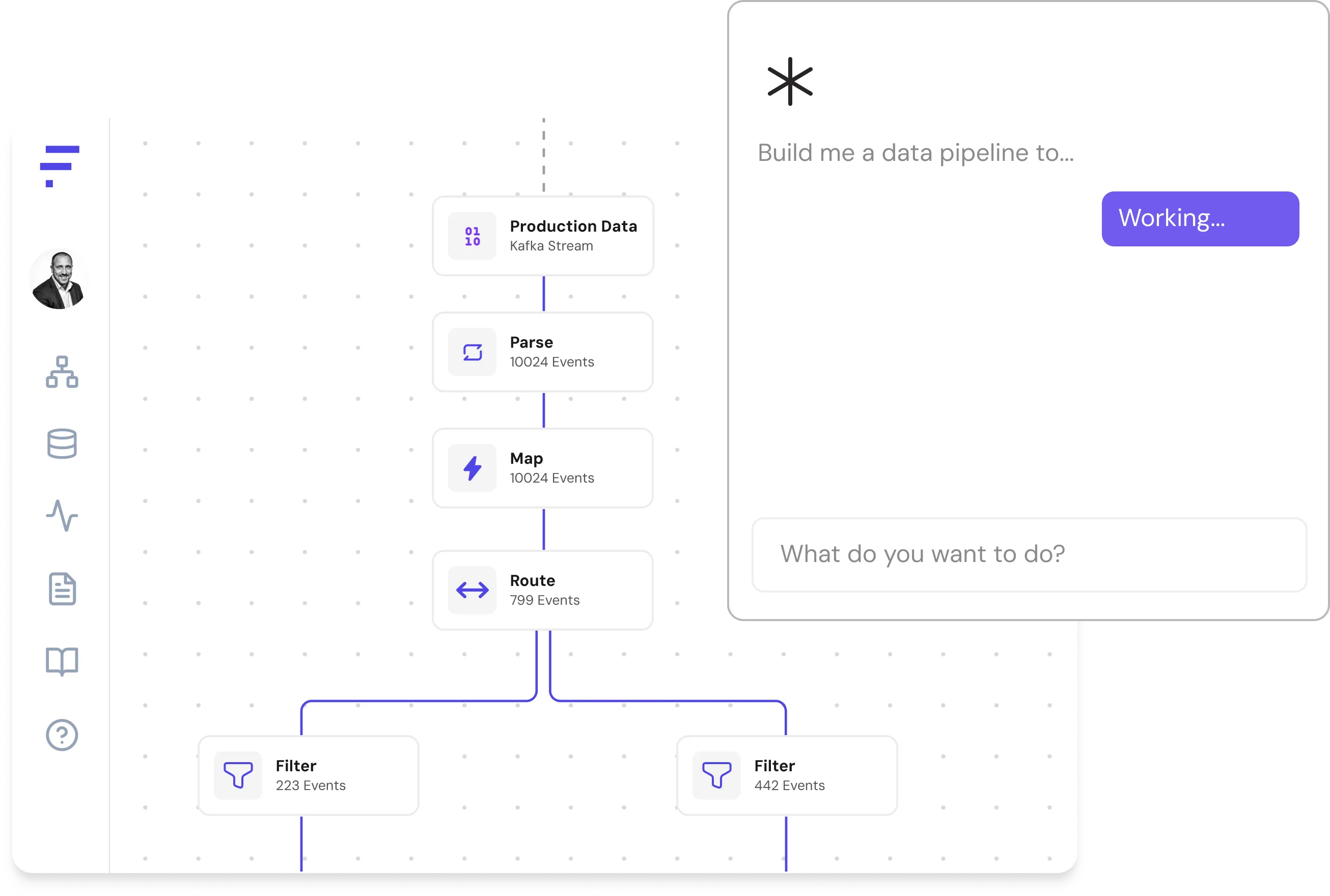
Use natural language to describe what you want to accomplish. Fleak's copilot will build it for you in minutes.
Identify event types, branches by destination intent, normalizes to the right schema. If your data changes, Fleak will update itself.
Clean, governed data in the schema you specify — to AI applications, data lakes, SIEM, or any destination. Real time. Zero storage.
Schema changed upstream? Fleak detects it, sends an alert, and generates a new config. All you have to do is approve and redeploy. No manual work. No on-call incidents.

30 minutes. Bring your messiest data source.