
What's the Best Alternative to Cribl Stream and AWS Glue for IoT Data Integration?
Enterprise data teams spend 78% of their time struggling with data orchestration and pipeline complexity, yet most organizations still rely on traditional ETL approaches that were designed for simpler, more predictable data landscapes. The fundamental challenge is not technical capability—it is an architectural mismatch between how legacy data integration tools work and how modern industrial systems generate data.
Why Data Pipeline Integration Costs Keep Rising
Machine-generated data from industrial equipment, IoT sensors, and operational systems creates significant operational overhead for large enterprises, with 80% of data scientists spending their time on data preparation rather than analysis. This stems from incompatible data formats, manual integration bottlenecks, and systems that break whenever vendors update their specifications.
Traditional data infrastructure treats this as a "schema mapping problem"—converting field names and data types from one format to another. This approach worked when data formats rarely changed and integration projects had 6-month timelines. Today, with IoT devices growing to 18.8 billion globally by the end of 2024 and vendors updating systems monthly, field mapping creates a maintenance nightmare that consumes engineering resources and delays business initiatives.
Comparing Leading Data Integration Platforms: Cribl, AWS Glue, and Palantir
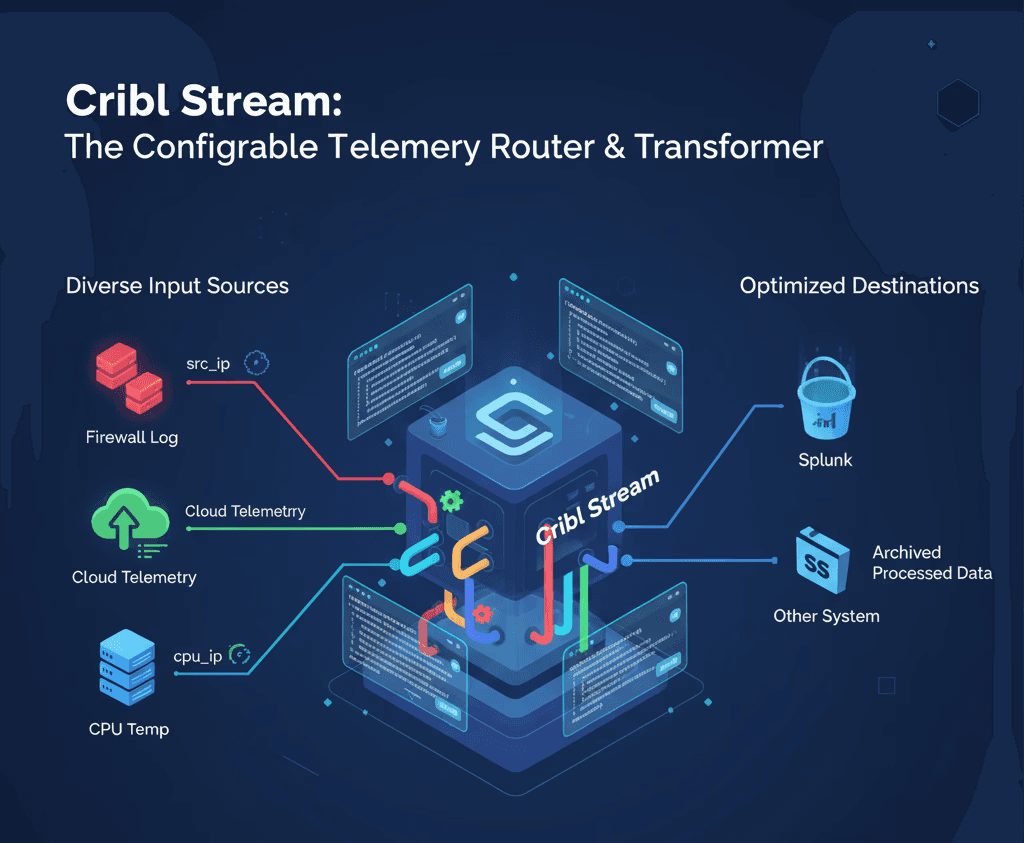
The Cribl Stream Approach: Telemetry Pipeline Processing
Cribl positions itself as the "Data Engine for IT and Security," providing sophisticated tools for collecting, routing, and transforming telemetry data. Organizations use Cribl Stream to create pipelines with functions that parse, filter, and transform data before sending it to destinations like Splunk or Amazon S3.
The system works through rule-based transformations using over 80 sources and destinations. When processing firewall logs alongside cloud service logs, users write functions to parse different formats and use rename operations to standardize field names. A security operations center might map a Cisco firewall's src_ip field to match AWS CloudTrail's sourceIPAddress field, creating consistent data for downstream analysis.
This approach handles scale well and offers considerable flexibility for telemetry data workflows. However, it requires manual rule creation and constant maintenance when source formats change—a common challenge in environments with frequent vendor updates.
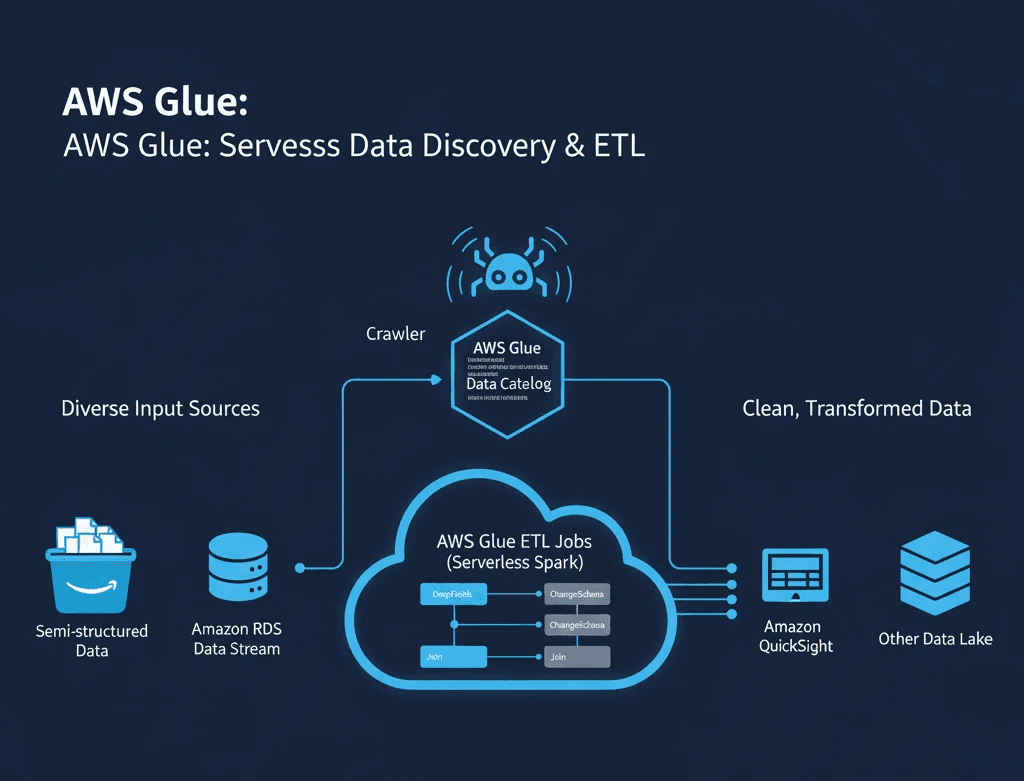
The AWS Glue Method: Serverless ETL with Automated Discovery
AWS Glue serves as a cornerstone for modern data warehousing with its serverless ETL capabilities. The service uses crawlers to automatically discover data schemas across various sources and stores metadata in the AWS Glue Data Catalog.
Transformations operate on DynamicFrames using functions like ChangeSchema, DropFields, and Join. Unlike traditional Spark DataFrames, DynamicFrames are schema-relaxed, making them ideal for semi-structured or evolving data formats like JSON or Parquet. A manufacturing company with sensor data spread across multiple S3 buckets can use Glue crawlers to catalog schemas automatically, then build visual ETL jobs to combine datasets.
While Glue automates schema discovery and provides visual transformation tools, it still relies on predefined transformation logic that requires updates when source schemas change. The crawler-based approach works well for batch processing but can introduce delays in real-time data integration scenarios such as: security incident response, IT service management, and ERP applications.
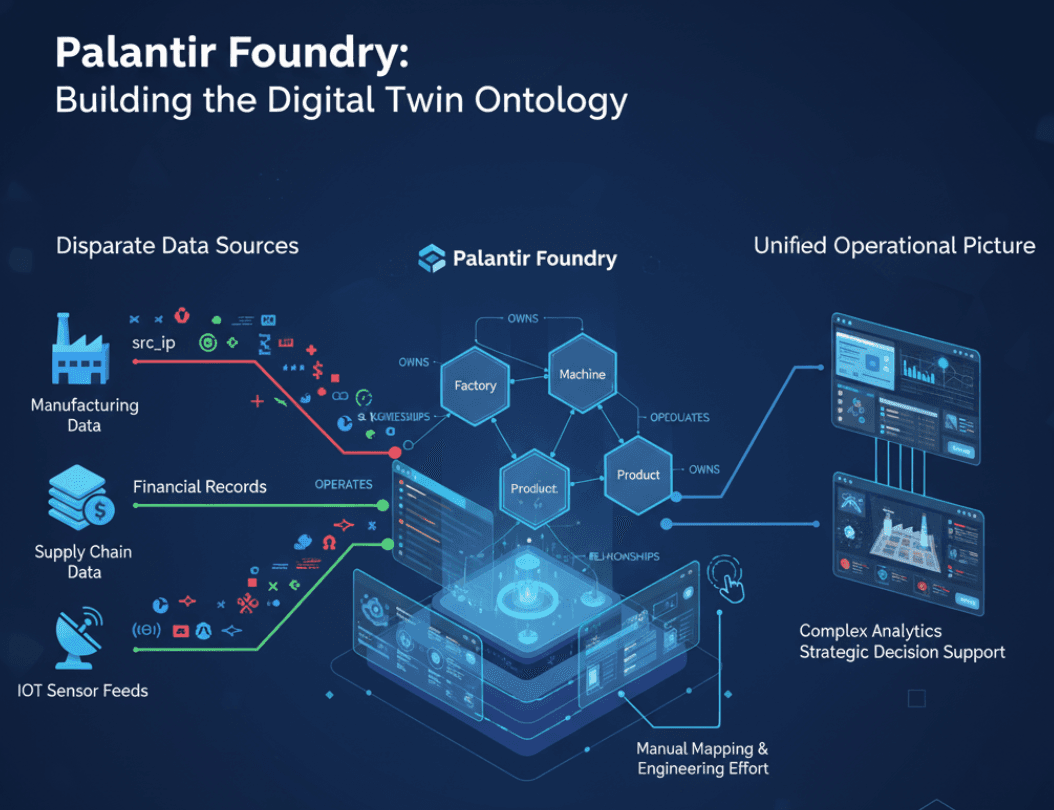
The Palantir Way: Ontology-Driven Integration
Palantir's Foundry and Gotham platforms integrate disparate datasets into unified ontologies for complex analytics. Foundry provides highly configurable data connectivity and integration tools that extend far beyond typical extract-transform-load (ETL) or extract-load-transform (ELT) solutions.
Organizations build data pipelines within Foundry using custom code to extract, clean, and normalize data from various sources. Engineers create explicit mapping logic to transform data into predefined ontology objects. This approach ensures high data quality and comprehensive operational pictures from multiple data sources.
While this method provides sophisticated analytics capabilities, each new data source or format change requires manual pipeline development, creating months of delays in accessing time-sensitive information. The ontology-building process demands significant engineering effort and domain expertise.
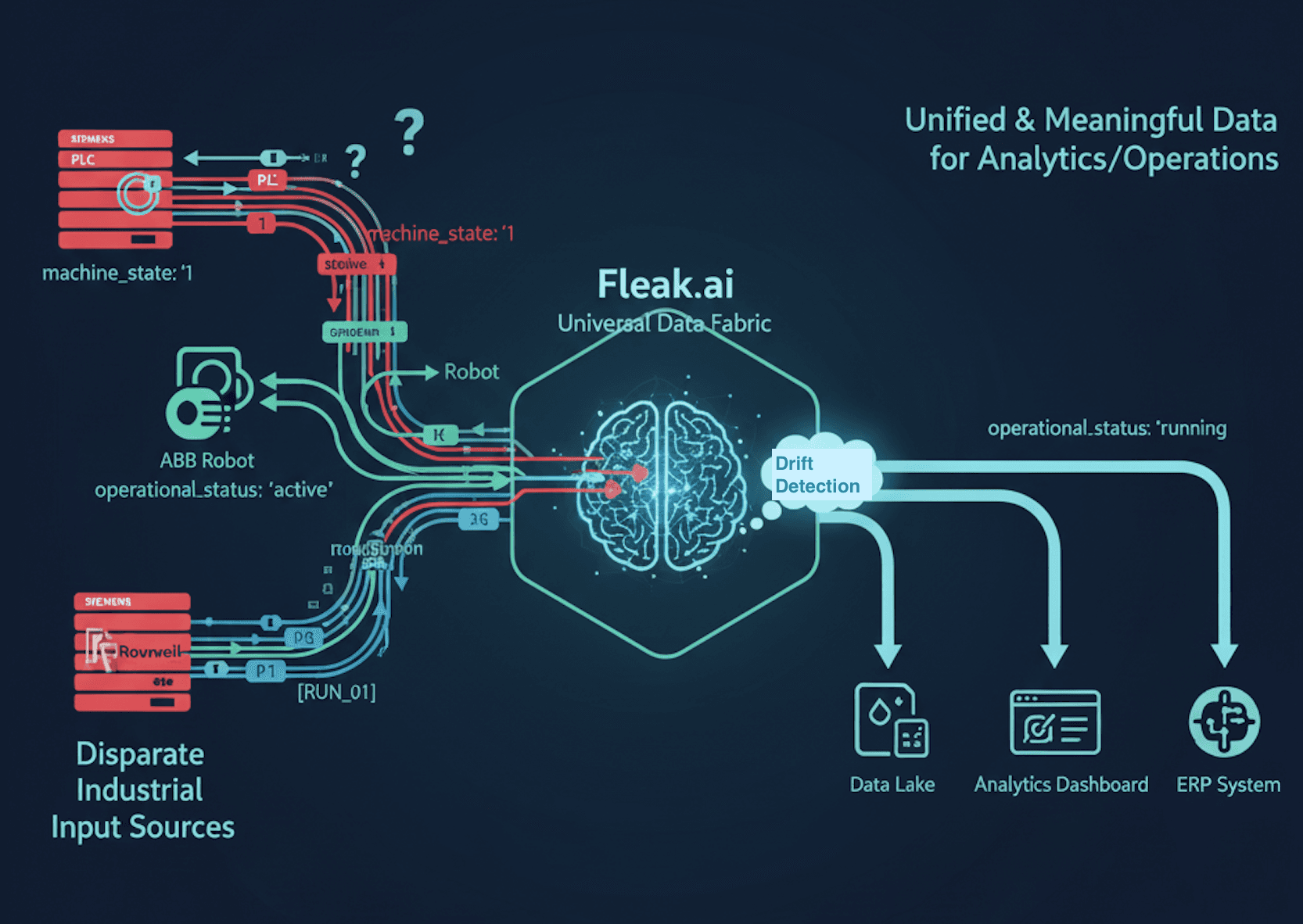
Schema Mapping vs Universal Data Translation: A New Approach
Traditional field mapping assumes the problem is structural—different names for the same data. The real challenge in industrial environments is understanding what data means regardless of how it is formatted. Just parsing or mapping the data and hoping for the best is not enough. What is required is a universal data translation fabric approach.
Consider a global automotive manufacturer operating equipment from Siemens, ABB, and Rockwell across their production lines. The complexity extends beyond simple field name differences:
Structural Variations:
- Siemens PLCs log machine status as flat fields:
machine_state: "running"with numeric codes (0=stopped, 1=running, 2=maintenance, 3=error) - ABB robots nest status data:
equipment: { operational_status: { current_state: "active", sub_states: ["welding", "positioning"] } } - Rockwell controllers use arrays:
status_codes: [101, 205, 330]where each number represents different operational conditions
Enum Translation Challenges:
- Siemens uses numeric codes for machine states
- ABB uses descriptive strings ("active," "idle," "fault")
- Rockwell uses proprietary codes ("RUN_01," "STP_02," "ERR_15")
- Each vendor's "error" state represents different underlying conditions (mechanical fault vs. safety stop vs. material shortage)
Nested Data Complexity:
- Temperature readings come as simple values from Siemens (
temp: 85.2) - Complex nested objects from ABB (
sensors: { thermal: { zone1: 85.2, zone2: 87.1, ambient: 22.5 } }) - Arrays from Rockwell (
temp_array: [85.2, 87.1, 22.5]where position indicates sensor location)
Traditional field mapping requires hundreds of transformation rules to handle these structural differences. When vendors update firmware or data schemas, multiple rules break simultaneously, creating the exact nightmare scenario that drives 78% of teams to spend most of their time on pipeline maintenance rather than strategic initiatives. When vendor firmware or data schemas change, each of the traditional platforms experiences a different type of disruption. For Cribl Stream, the pain is in constant manual rule updates. Its rule-based transformation requires engineers to manually adjust functions whenever a source format changes, leading to a maintenance nightmare. AWS Glue's challenge lies in its automated but reactive approach. Its crawlers have to re-run to discover and catalog the new schema, and the predefined transformation logic needs to be updated, which can introduce delays, especially in real-time scenarios. Finally, for Palantir Foundry, the issue is the intensive engineering effort required to maintain its ontology. Each format change necessitates rebuilding custom data pipelines and mapping logic to fit the new data into the predefined ontology, causing delays of months in accessing time-sensitive information.
Instead of just mapping field structures, a universal data translation fabric understands the business meaning of your data. Think of it like a smart translator that knows a Siemens code of "1," an ABB string of "active," and a Rockwell code of "RUN_01" all mean the exact same thing: "equipment operating normally." The system understands the meaning behind the data, not just its format.
This is a fundamental shift in how you treat your data.
Schema-on-Read: This is a conventional approach used by many modern data lake platforms and even federated search engines like Query.ai. Data is ingested as-is, and you apply the structure at the time you query it. While this can be flexible, it pushes all the complexity to the last minute—exactly when you need a fast, reliable answer.
Schema-on-Write: This is the Fleak.ai approach. Our AI-native system resolves the data’s meaning immediately upon ingestion. It automatically adapts to vendor changes without manual intervention, creating consistent, ready-to-use data for your team in real time. For industrial IoT data, where frequent schema changes are the norm, this approach offers a more sustainable and efficient path forward.
The Business Case for Universal Data Translation Fabric
The question every IT leader faces: how long should data integration actually take? Current reality shows that traditional platforms require 6+ months per source due to custom mapping development, with 57% of teams reporting business needs changing before integration completion. When formats change, teams scramble to fix broken pipelines, delaying business initiatives, reducing data quality,consuming valuable technical talent and making real-time responsiveness impossible
A Universal Data Translation Fabric offers a fundamentally different approach by understanding meaning rather than structural formats, potentially reducing integration timelines to 1-2 weeks while eliminating ongoing maintenance overhead. This dramatic improvement stems from the fact that many data platforms, including Cribl Stream, AWS Glue, and even modern data lakehouses like Databricks, still rely on predefined rules or schemas that require manual intervention when IoT vendors update firmware or data formats.
Cribl Stream and AWS Glue rely on manual rule creation and crawler management, which become a maintenance nightmare at scale.
Databricks's Delta Lake provides a flexible schema and ACID transactions, which is a major step forward. However, it still requires data engineers to manage schema evolution and complex data pipelines to handle the highly diverse, multi-vendor data streams common in industrial IoT.
With 18.8 billion connected devices generating diverse formats, manual maintenance for any of these approaches becomes unsustainable. The universal data translator solves this by using AI to automatically understand the business meaning of the data upon ingestion, eliminating the need for engineers to constantly fix broken pipelines.
The results speak for themselves in industrial implementations, particularly in manufacturing, aerospace, energy, cybersecurity and other industrial sectors dealing with multi-vendor equipment data where frequent vendor updates and complex operational technology integration requirements create the biggest challenges:
- Significant cost reductions in data integration projects compared to traditional approaches
- Real-time visibility across previously siloed vendor equipment
- Engineering resource optimization allowing teams to focus on building new capabilities rather than maintaining existing integrations
- Universal data translation capabilities to enable the next generation of industrial AI implementations
While initial costs vary between different approaches, organizations typically see 60-90% reduction in ongoing integration maintenance costs, plus faster time-to-value for new data sources and reduced engineering overhead. The business impact extends beyond cost savings—when integration becomes fast and reliable, organizations can respond quickly to changing business requirements, onboard new data sources without project delays, and make data-driven decisions with confidence in data quality and consistency.
But here's what many organizations want to know: which approach makes sense for their specific situation? The choice depends largely on your data sources, organizational priorities, and technical requirements.
From Integration Maintenance to Business Value
The shift from schema mapping to universal data translation represents a fundamental change in how organizations handle data integration. Instead of spending the majority of engineering time maintaining brittle transformation rules, teams can focus on extracting business value from unified, consistent data that is AI-ready.
Traditional ETL tools solved yesterday's problems—when data formats were stable and changes were infrequent. Today's operational reality, with IoT market value projected to increase from $62.1 billion to $200.3 billion by 2030, demands systems and AI solutions that understand data meaning as naturally as human experts do, while operating at the scale, speed and quality that modern business requires.
For organizations dealing with diverse data sources, frequent vendor updates, and complex integration requirements, universal data translation offers a path toward sustainable data infrastructure that improves rather than degrades over time. Companies exploring this approach, such as those building solutions around universal data translation, are addressing these fundamental challenges in how we think about data transformation and integration.
The question is - how quickly organizations can make the transition to stay competitive in an increasingly AI and data-driven landscape.
Platform Comparison: Which Tool Is Right for You?
|
Feature |
Cribl Stream |
AWS Glue |
Palantir Foundry |
Universal Data Translation |
|
Setup Time |
4-6 weeks |
8-12 weeks |
12+ weeks |
1-2 weeks |
|
Maintenance |
High (rule updates) |
Medium (crawler management) |
High (custom pipelines) |
Low (self-adaptive) |
|
IoT Support |
Limited telemetry focus |
Basic batch processing |
Complex custom development |
Native real-time |
|
Schema Changes |
Manual rule updates |
Crawler re-runs required |
Pipeline redevelopment |
Automatic adaptation |
|
Best For |
Security/IT operations |
AWS-native environments |
Enterprise analytics |
Industrial data ingestion |
The choice between these platforms often comes down to your specific operational context and long-term strategic goals. Organizations focused primarily on security and IT operations telemetry might find Cribl Stream's specialized routing capabilities align well with their needs, especially if they have dedicated DevOps teams capable of managing sophisticated pipeline configurations.
For companies operating within AWS-native cloud environments, AWS Glue's serverless architecture and pay-per-use pricing model offers compelling advantages, particularly when working with well-defined, relatively stable data schemas where batch processing workflows are acceptable.
Enterprises requiring comprehensive analytics platforms with significant engineering resources often gravitate toward Palantir Foundry's advanced ontology-driven approach, though this requires substantial budget allocation and tolerance for complex implementation timelines.
However, organizations managing industrial IoT or operational technology data—where frequent vendor updates and schema changes are the norm—increasingly find that universal data translation approaches offer the most sustainable path forward, reducing long-term engineering overhead while enabling real-time integration capabilities.
Ready to see how Fleak.ai can transform your data?
Discover how universal data translation can reduce your integration timelines and eliminate maintenance overhead. Click here to schedule a call with one of our founding engineers and see a demo of our platform
References
- Data Integration Adoption Rates in Enterprises – 45 Statistics Every IT Leader Should Know in 2025 - Integrate.io, 2025
- State of IoT 2024: Number of connected IoT devices growing 13% to 18.8 billion globally - IoT Analytics, April 2025
- Industrial IoT Market & Use Cases Statistics for 2025 - ITTransition, 2025
- Data Integration Market Size, Share | Global Growth [2033] - Astute Analytica, January 2025
- Cribl: The Data Engine for IT and Security - Cribl Official Documentation
- ETL Service - Serverless Data Integration - AWS Glue - Amazon Web Services
- What is AWS Glue? - AWS Glue Documentation - AWS Documentation
- Overview • Data integration • Palantir - Palantir Technologies
- Real-Time Data Integration Statistics – 39 Key Facts Every Data Leader Should Know in 2025 - Integrate.io, 2025
- IoT in Manufacturing: Applications Today and the Future - Hitachi Solutions, April 2024
- Telemetry 101: What It Is and How It Helps - Cribl Glossary
- Master ETL on AWS with Glue DynamicFrames: A Beginner's Guide - May 2025
- Overview • Ontology • Palantir - Palantir Documentation