
This blog presents an architectural approach that combines artificial intelligence with runtime execution systems to create self-adapting data processing pipelines. The architecture, structured as an intelligence-execution pattern, enables systems to learn from operational patterns and automatically adjust processing configurations while maintaining system stability.
Early experiments of this architecture have shown substantial improvements in operational metrics, including reduced processing failures and decreased configuration maintenance requirements. The pattern has shown particular efficacy in domains requiring rapid adaptation to changing conditions, such as cybersecurity log processing and supply chain optimization systems.
The Evolution of Service Integration Challenges
Modern organizations increasingly rely on complex service orchestration to handle their critical business operations. As organizations evolve, their operation needs change, data formats shift, and edge cases multiply. Traditional processing systems, with their static configurations and manual management approaches, increasingly show their limitations. A major financial institution's fraud detection system requires orchestrating data flows across multiple services - transaction monitoring, customer profile analysis, third-party risk scoring, and regulatory compliance checking. Their engineering team spent three months updating integration configurations when they needed to incorporate a new type of transaction monitoring rule for instant payments. The update required modifications to data transformation logic across five different services, each with its own processing rules and error handling requirements. What should have been a straightforward addition of new fraud detection patterns became a complex project due to intricate dependencies in their service orchestration configuration.
Consider how service interactions typically evolve within growing organizations. Enterprise systems today face a perfect storm of challenges under exponential data explosion and AI adoption pressure. Input data quality varies wildly, business requirements change frequently, and processing rules need constant updates. When an execution pipeline fails, the investigation process is often painfully manual: engineers must analyze system logs, attempt to reproduce issues and patch configurations with limited contextual understanding. This reactive approach often leads to cascading issues, where by the time one configuration issue has been fixed, three more variations of the same problem have already filled your error queues.
Service orchestration configurations, which define how data and operations flow across distributed systems, were originally designed to make systems flexible, and have paradoxically become a primary source of system fragility. A typical enterprise processing pipeline involves extensive sets of configuration parameters spanning data validation rules, transformation logic, and output formatting. These configurations develop complex interdependencies over time, often making changes risky and unpredictable. In one documented enterprise deployment, a production system's configuration grew to over 2,000 lines of intricate parameters and rules. As described by a senior systems architect: : "We had a 2,000-line configuration file that nobody wanted to touch. Making changes was like performing surgery blindfolded - we never knew what side effects might emerge."
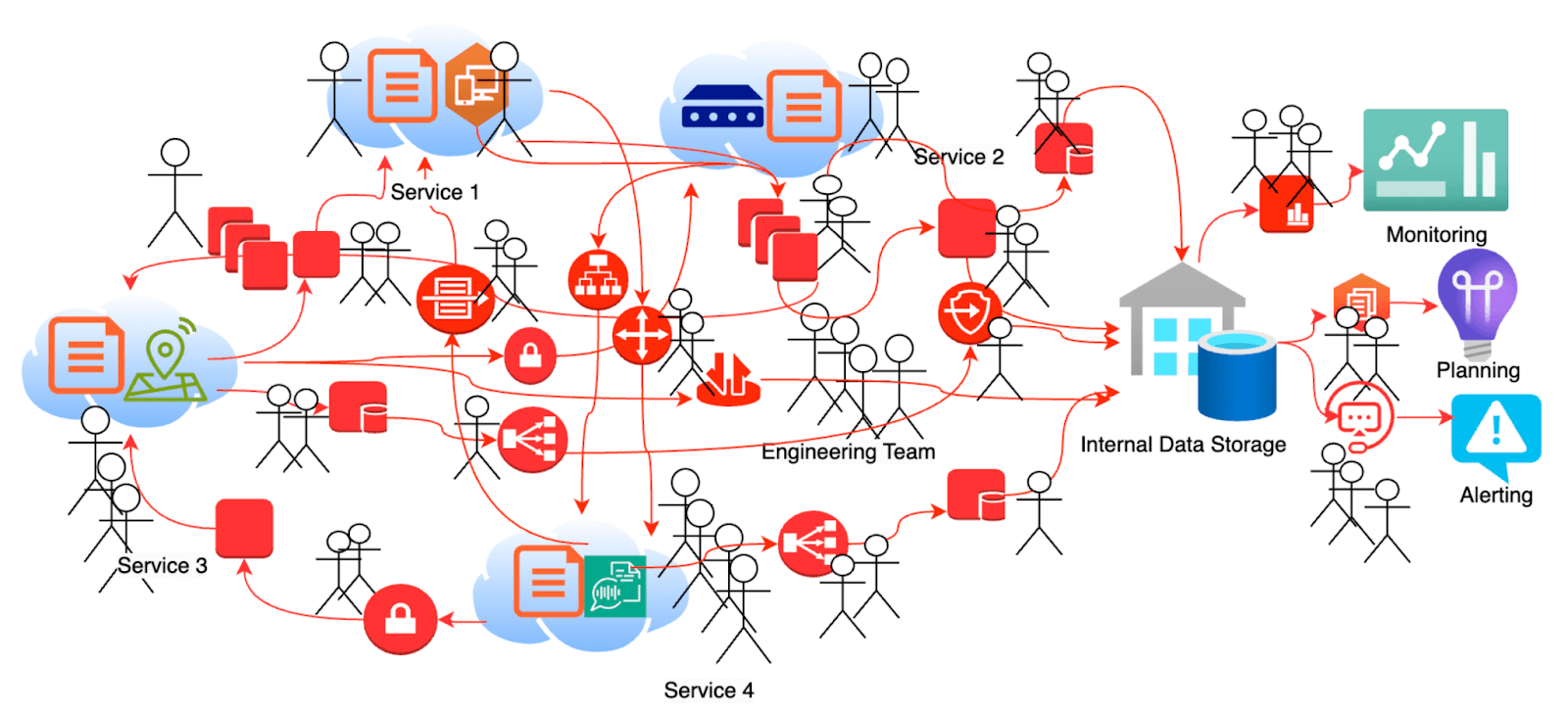
The true cost of maintaining traditional processing systems goes far beyond the obvious metrics. While the time spent fixing failed jobs and updating configurations is significant. The broader organizational impact is more profound caused by delayed business decisions while waiting for data pipeline fixes, the accumulated technical debt from quick configuration patches, and the organizational knowledge lost when key team members leave. Every hour spent manually tweaking configurations is an hour not spent building new features or improving system architecture.
The fundamental problem is an architectural misalignment: The application of static configuration approach to solve inherently dynamic operational requirements. System processing rules must adapt to evolving data patterns, changing business requirements, unforeseen edge cases, and variable load patterns. Traditional approaches present organizations with an architecture dilemma: implement systems so generic they handle everything (but optimize for nothing), or specialize to handle a particular scenario (and accept the limit of capabilities).
While organizations clearly recognize that the current approach is not sustainable, the path forward requires rethinking fundamental assumptions about data processing systems. Considering the possibility of breaking free from the cycle of reactive fixes and manual updates, the need for a more adaptive, intelligent approach has never been more clear. Imagine an adaptive architecture where the systems could learn from its failures, suggest improvements, and evolve at its configuration dynamically - all while still keeping essential human oversight of critical decisions.
A New Approach: The Brain-Muscle Architecture
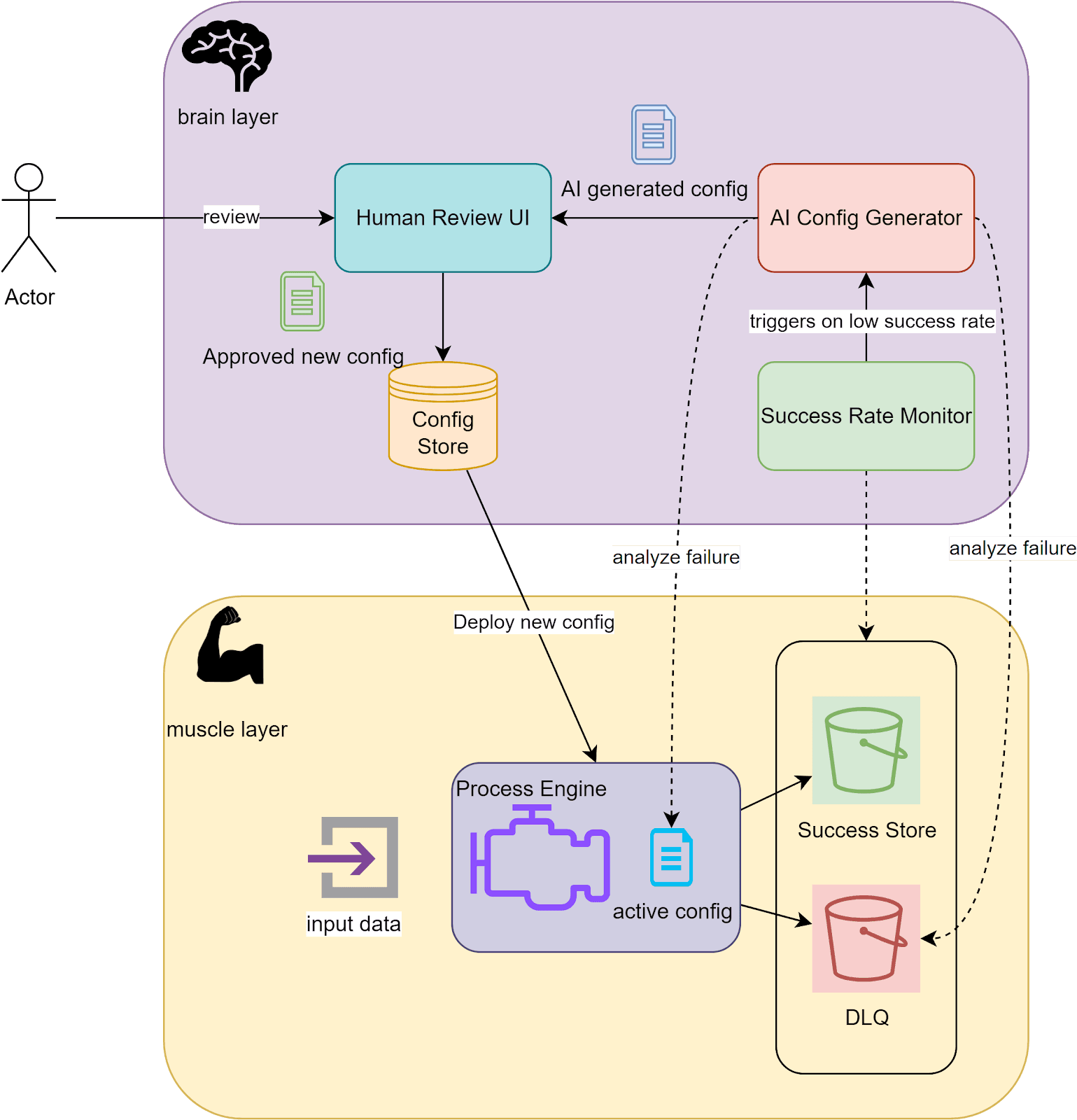
Building upon the unified processing foundation described in our previous work on data pipelines and microservices integration, we present an architectural pattern that adds adaptive intelligence to runtime operations. This architecture separates processing execution from operational intelligence, creating distinct 'muscle' and 'brain' layers that work in concert to deliver both processing efficiency and adaptive capabilities.
The execution layer (the muscle) in our architecture is powered by the unified processing engine previously detailed - the same engine that provides consistent runtime behavior across synchronous API operations and asynchronous data pipelines. Our engine acts as a highly efficient factory floor where data flows through various processing stations, each configured to perform specific operations. When everything goes smoothly, processed data flows to its destination. When something goes wrong, the failure is captured in a dead letter queue, preserving the problematic data and the context of what went wrong.
The intelligence layer (brain) introduces adaptive capabilities that fundamentally transform how processing configurations evolve. While traditional monitoring systems simply alert on failures, this layer implements a continuous learning loop. It continuously monitors the success rate of data processing across predefined time horizons. When the success rate drops below acceptable thresholds, the AI configuration generator analyzes failure patterns from the DLQ(dead letter queue) and correlates them with current configuration settings to generate new configuration proposals.
But unlike a fully automated system that might make risky changes, the brain layer maintains human oversight through a structured review process. When the AI agent generates new configuration proposals, they are presented through a human review interface that enables operators to examine, modify, and approve changes before deployment. This approach combines the scalability of automated analysis with the critical judgment of experienced operators. Once approved, new configurations are stored in a versioned configuration store and deployed to the execution layer, where their effectiveness is continuously monitored to ensure improved processing outcomes.
As illustrated in the architectural diagram below, this design creates a closed feedback loop between operational execution and intelligent adaptation. The brain layer continuously learns from actual processing outcomes, while the muscle layer efficiently executes the optimized configurations. This separation of concerns enables each layer to evolve independently while maintaining system stability through controlled configuration updates.
Building Intelligence into Error Recovery
At its core, any resilient data processing system needs robust error handling. But we took this a step further - rather than just catching failures, we designed our Dead Letter Queue to be the foundation for system intelligence. When processing fails runtime validation rules, the DLQ captures not just the problematic data, but rich contextual information about what went wrong. This error context becomes invaluable training data for our AI-driven adaptation.
One subtle but critical aspect of the DLQ design is how it maintains clean separation between processing runs. Each iteration of our configuration creates its own error profile, preventing the conflation of different failure patterns. This segmentation proves essential when validating configuration changes - we can definitively measure whether a new configuration resolves specific historical issues before applying it to fresh data.
The monitoring system acts as a sophisticated circuit breaker, watching for signs of degraded processing quality. Rather than relying on simple error counts, it tracks composite success metrics that can be tuned to the specific requirements of each business domain. When these metrics fall below defined thresholds for a specified duration, the system automatically pauses processing to prevent error cascades and initiates the configuration regeneration workflow.
This is where the AI component demonstrates its value. The configuration generation process analyzes three distinct data streams: the current failure patterns from the segmented DLQ, the existing configuration that led to those failures, and - crucially - a knowledge base of business rules and constraints provided by domain experts. This multi-faceted analysis allows it to propose targeted configuration updates that address immediate processing failures while respecting broader system invariants.
However, we recognized that human judgment remains invaluable. The review process is designed to leverage expert knowledge efficiently through a streamlined validation workflow. When reviewing proposed configuration changes, operators can execute test runs against historical failure cases from the DLQ, verifying fixes with real-world data before deployment. The version control system maintains a complete history of configuration changes and their corresponding validation results, enabling rollback if needed.
Once approved, configuration deployment follows a carefully orchestrated sequence. The processing engine restarts with the new configuration and first attempts to process the segmented historical data from the DLQ. This provides an immediate verification of the fix effectiveness. Only after successfully processing this test data does the system resume handling new inputs. Through this methodical approach to deployment, we maintain system stability while enabling continuous improvement through learned adaptations.
This interplay between automated intelligence and human expertise transforms what would traditionally be a reactive error handling process into a proactive cycle of continuous reliability improvement. The system learns from its failures but does so under careful oversight, combining the scalability of machine learning with the irreplaceable wisdom of human operators.
A case study
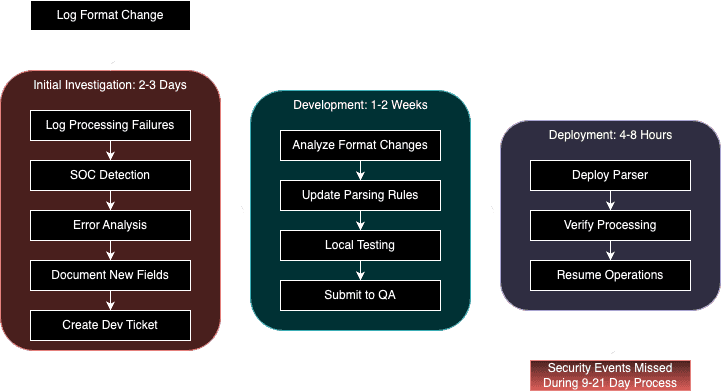
Consider a real-world scenario in cybersecurity operations: A financial institution's security monitoring system processes millions of authentication logs daily across their cloud and on-premise applications. When a major cloud provider updates their log format to include new fields for tracking user device fingerprints, traditional systems would typically fail to process these logs, potentially missing critical security events. The operations team would need to manually analyze the new format, update parsing rules, and deploy changes—a process that could take days.
With the adaptive intelligence architecture, the system responds differently. The brain layer would notice the dropping success rate of these authentication logs within minutes. The AI agent, analyzing the dead letter queue, identifies that 40% of failing logs contain new device fingerprint fields not covered by current parsing rules. Instead of just alerting about the problem, it generates an updated configuration that preserves the existing parsing logic while accommodating the new fields. After a human security engineer reviews the proposed changes through the human review interface and approves the updates. The muscle layer will deploy the new configuration and automatically reprocess the failed records, ensuring no security events are missed.
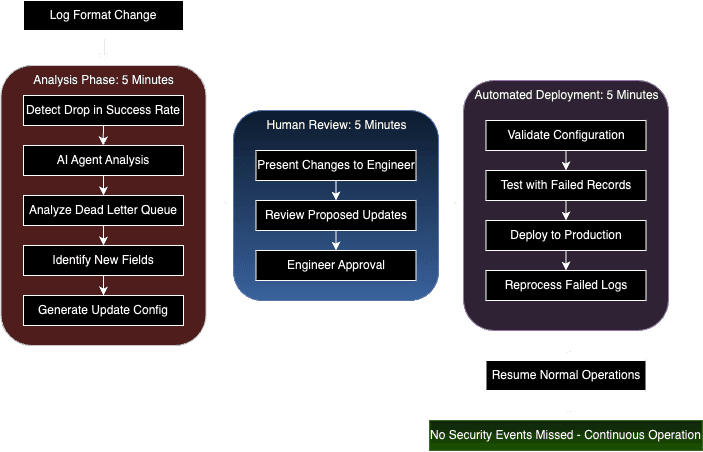
This automated adaptation, combined with human oversight, transforms what would have been a multi-day incident into a 15-minute configuration update. The AI handles the heavy lifting of analyzing failures and proposing solutions, while humans provide the business context and final approval. The configuration deployment process follows a rigorous sequence - the system first validates proposed changes by processing previously failed records, confirming the effectiveness of new configurations before transitioning to full operational deployment. This methodical approach ensures both rapid adaptation and operational stability.
Conclusion
The adaptive processing architecture presented here aims to address fundamental challenges in service orchestration and configuration management. Initial implementations in IoT and cybersecurity domains demonstrate the architecture's potential for reducing operational complexity while improving system reliability. Early testing suggests promising results, with significant reductions in processing failures and manual configuration changes.
The ongoing development of this architecture represents a step towards more adaptive enterprise systems. As organizations continue to face growing complexity in their service interactions, the need for intelligent, self-adjusting configuration management becomes increasingly important. Through continued collaboration with domain experts and system operators across industries, this architecture will evolve to address emerging challenges within different sectors.