Fleak joins Databricks AI Accelerator Program ->
Forget About Data Ingestion
Forget About Data Ingestion
Ingest, transform, and normalize complex data in minutes, then deploy anywhere — automatically fixing schema drift and delivering consistent, clean, AI-ready output to any destination.
Ingest, transform, and normalize complex data in minutes, then deploy anywhere — automatically fixing schema drift and delivering consistent, clean, AI-ready output to any destination.


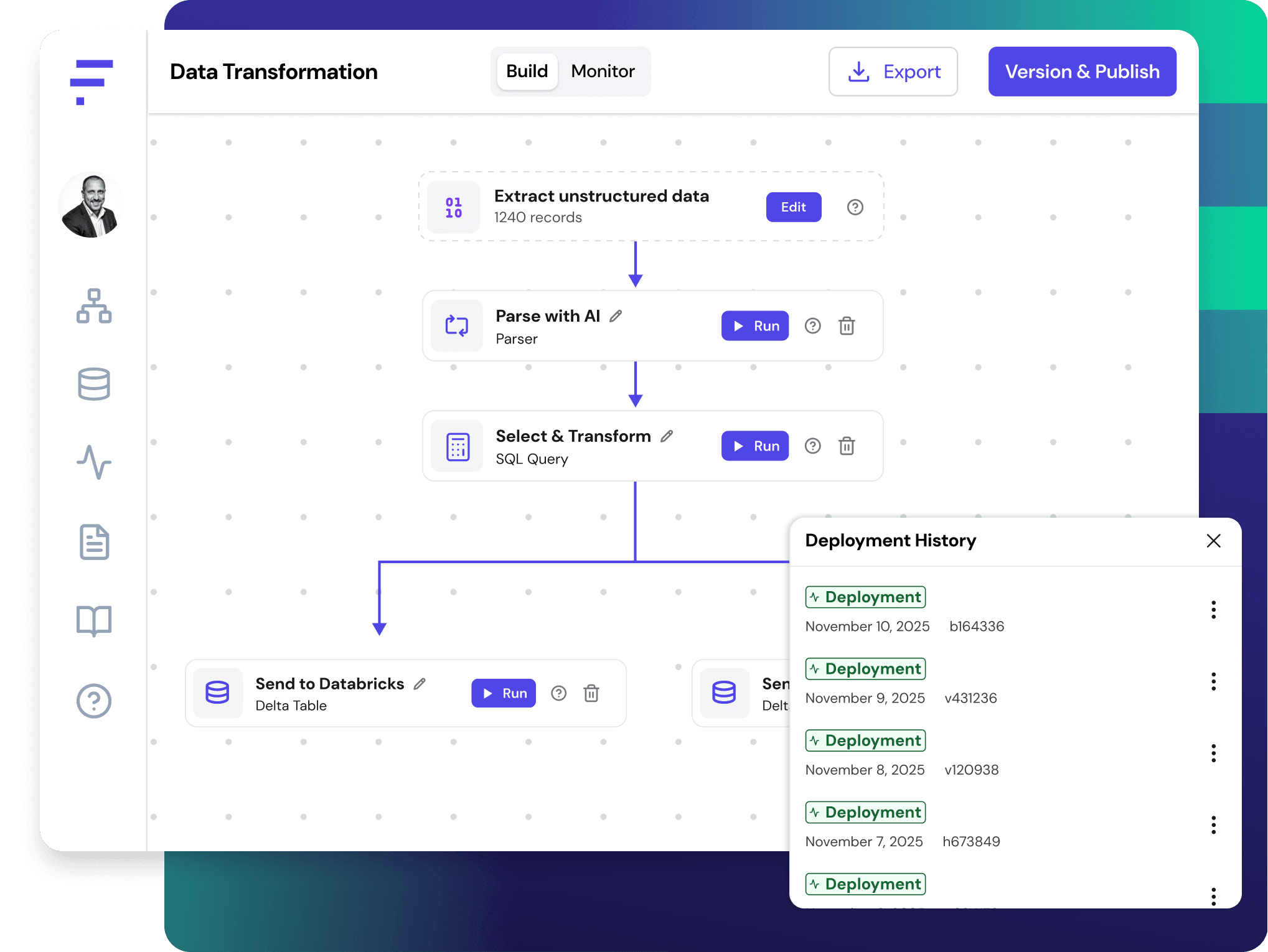
Stop Losing Revenue to Brittle Data
Stop Losing Revenue to Brittle Data
Your Data Pipelines Need a Brain
Your Data Pipelines Need a Brain
Fleak is your Intelligence Upgrade. Maximize the ROI of your existing data infrastructure and enable strategic platform consolidation at hyperspeed.
Fleak is your Intelligence Upgrade. Maximize the ROI of your existing data infrastructure and enable strategic platform consolidation at hyperspeed.
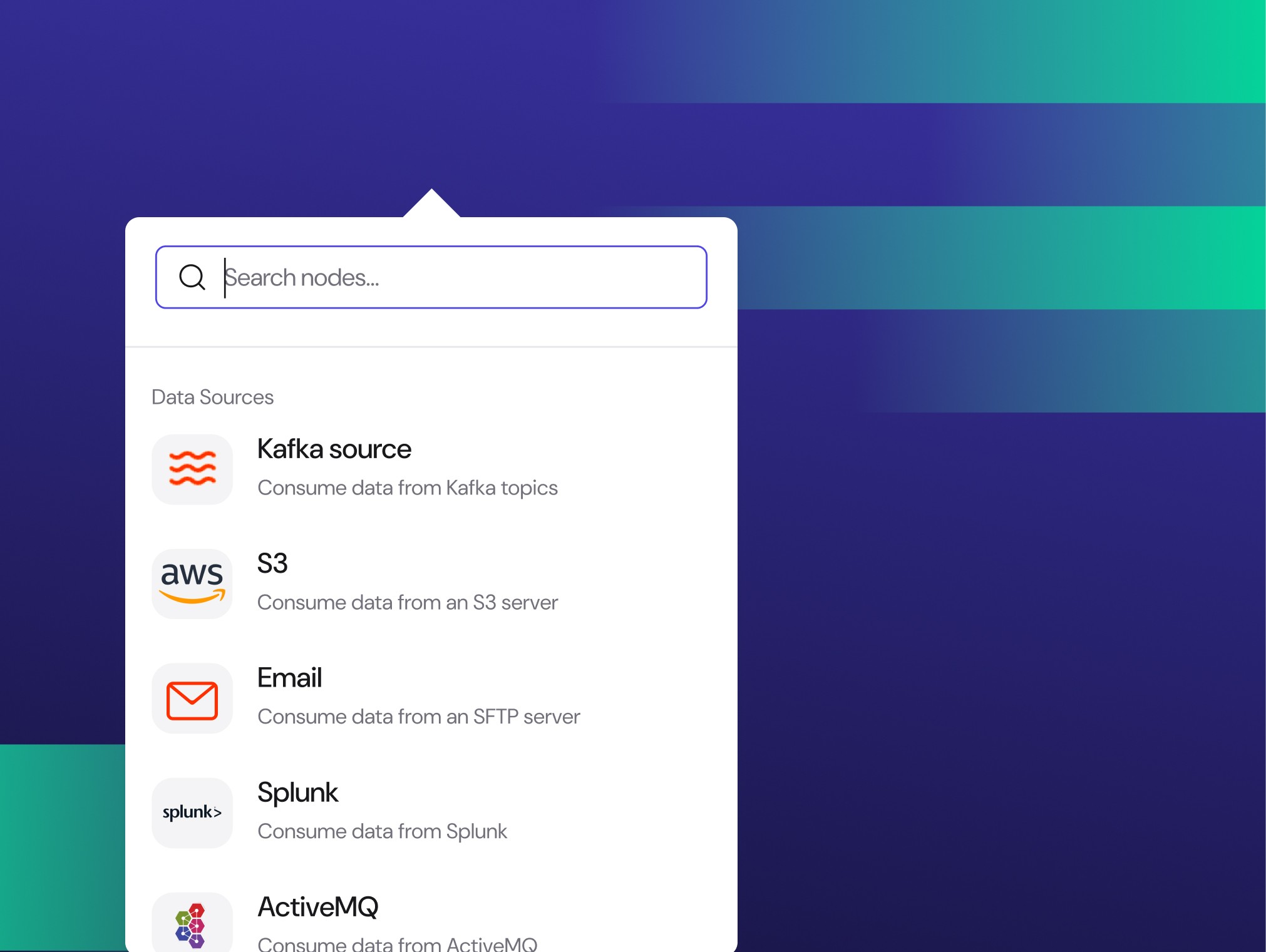
Onboard Data Sources in Hours
Add new data sources, in hours, not months, enabling immediate monetization and partner activation.
Add new data sources, in hours, not months, enabling immediate monetization and partner activation.
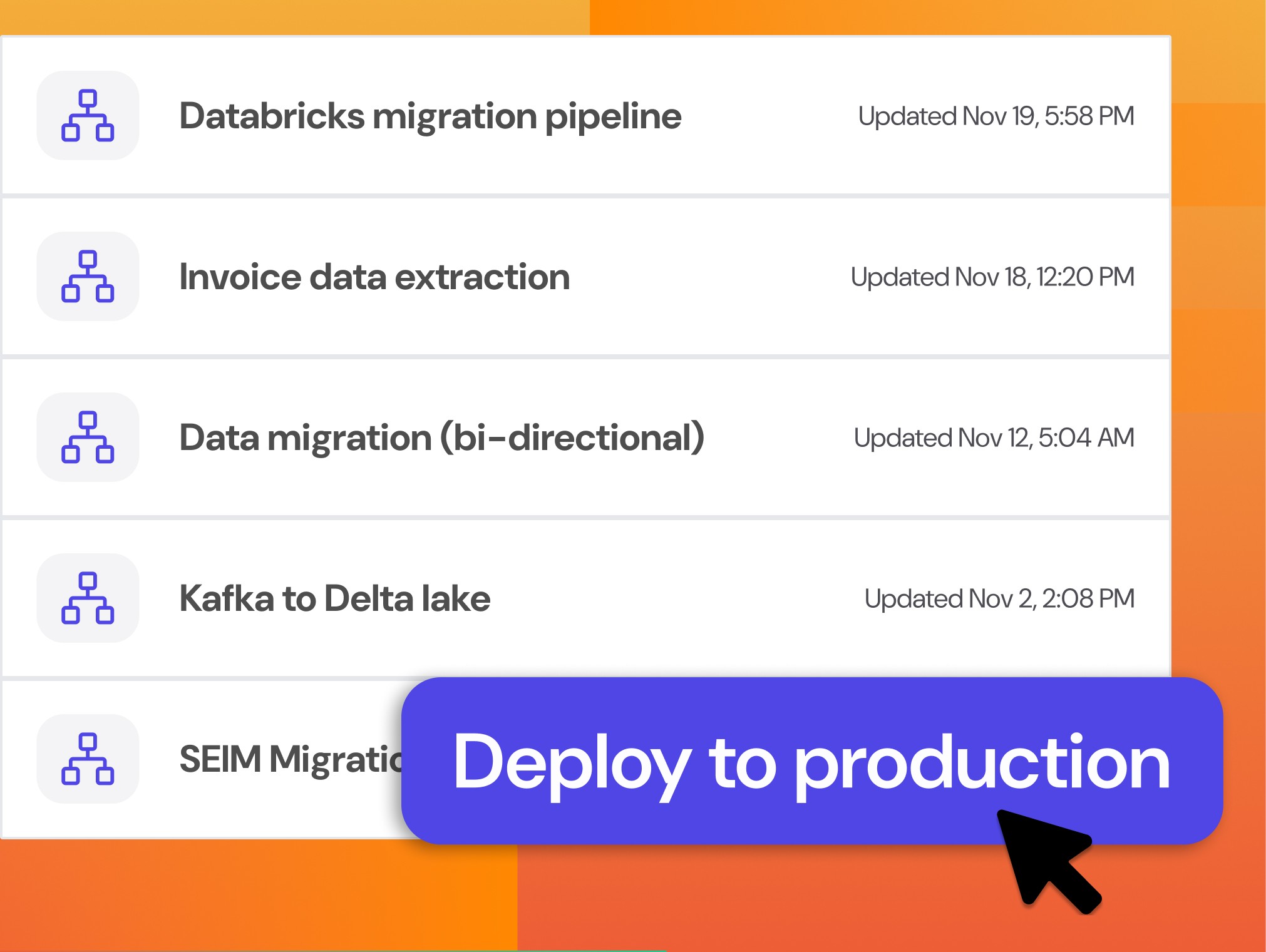
Avoid Capacity Drain
Free up 90%+ of engineering time to focus on building new detection models or AI products, instead of simply sustaining existing infrastructure
Free up 90%+ of engineering time to focus on building new detection models or AI products, instead of simply sustaining existing infrastructure
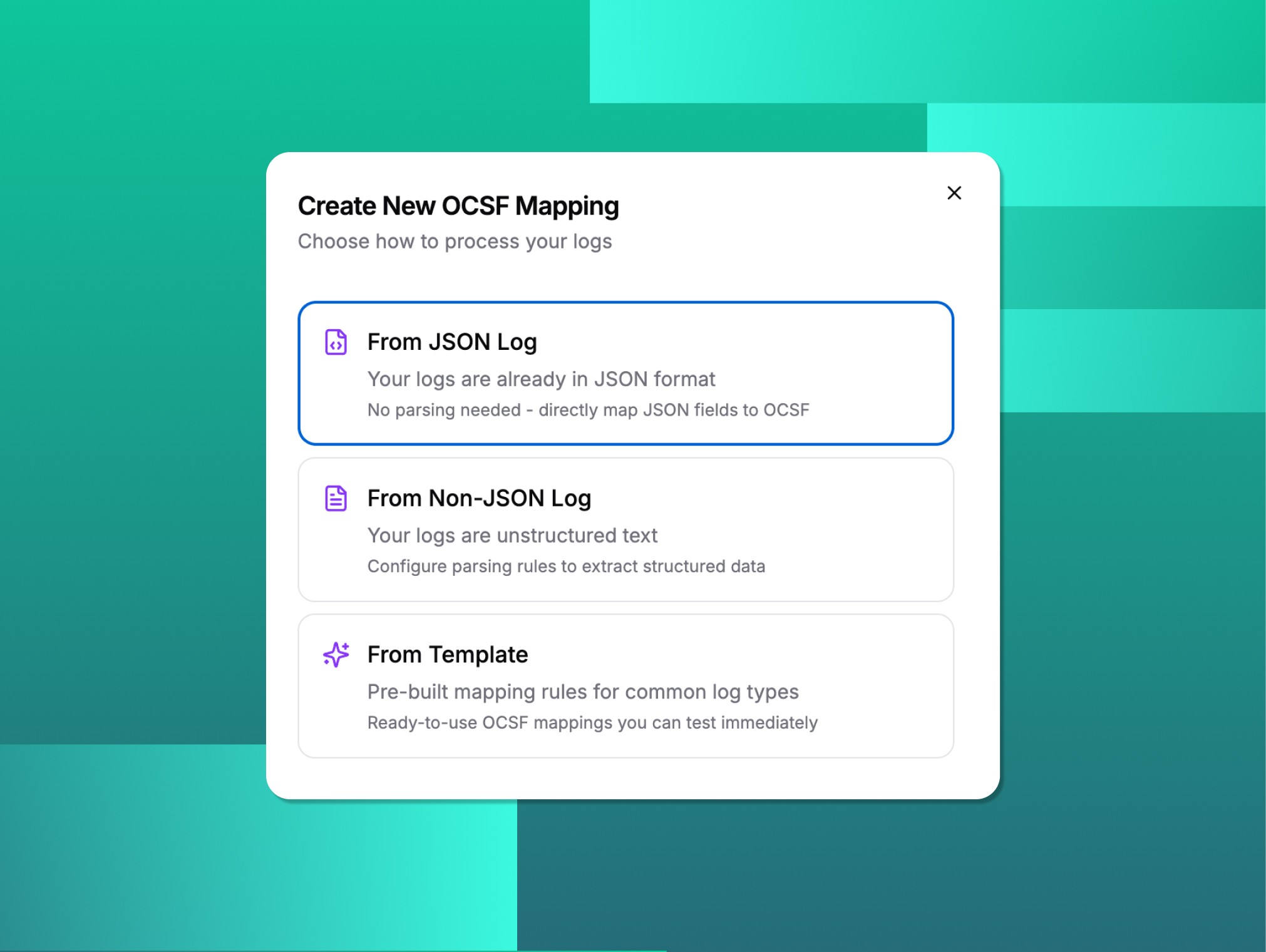
De-Risk Data Integrity
Achieve 90%+ field accuracy on complex data models, whether mapping complex Security Schemas like OCSF or integrating proprietary industrial data (e.g., invoices, transactions, device logs).
Achieve 90%+ field accuracy on complex data models, whether mapping complex Security Schemas like OCSF or integrating proprietary industrial data (e.g., invoices, transactions, device logs).

Trusted by Global Leaders in Data Infrastructure and Security
We are embedded within the data infrastructure of industry leaders, solving the most demanding data transformation challenges.
We are embedded within the data infrastructure of industry leaders, solving the most demanding data transformation challenges.




Break Down Data Silos, Develop Better AI Insights
Break Down Data Silos, Develop Better AI Insights
Fleak breaks down data silos by transforming and moving data across systems with the click of a button. Instead of struggling for months with fragmented implementations, your teams can normalize how data flows, reduce integration overhead, and unlock faster, AI-ready insights across your enterprise.
Fleak breaks down data silos by transforming and moving data across systems with the click of a button. Instead of struggling for months with fragmented implementations, your teams can normalize how data flows, reduce integration overhead, and unlock faster, AI-ready insights across your enterprise.

AI-Native Config Generation
Fleak AI instantly creates full, executable and scalable transformation logic by analyzing documentation and sample data.

Avoid Vendor Lock-in
Generate engine-agnostic configuration and maximize ROI on existing infrastructure by deploying Fleak anywhere — Apache Spark, Flink, Vector, even our open-source Zephflow engine.

Forget Data Drift
Never let changing data derail your team — Fleak automatically detects schema drift, generates a corrected configuration, and pushes a human-reviewed fix to your pipeline.

Deploy Flexibly
Air-Gapped and Hybrid Ready: Deploy your Fabric on-prem, in your VPC, or at the edge to meet strict compliance and feed a consolidated data lake

AI-Native Config Generation
Fleak AI instantly creates full, executable and scalable transformation logic by analyzing documentation and sample data.
Fleak AI instantly creates full, executable and scalable transformation logic by analyzing documentation and sample data.
Avoid Vendor Lock-in
Generate engine-agnostic configuration and maximize ROI on existing infrastructure by deploying Fleak anywhere — Apache Spark, Flink, Vector, even our open-source Zephflow engine.
Generate engine-agnostic configuration and maximize ROI on existing infrastructure by deploying Fleak anywhere — Apache Spark, Flink, Vector, even our open-source Zephflow engine.
Forget Data Drift
Never let changing data derail your team — Fleak automatically detects schema drift, generates a corrected configuration, and pushes a human-reviewed fix to your pipeline.
Never let changing data derail your team — Fleak automatically detects schema drift, generates a corrected configuration, and pushes a human-reviewed fix to your pipeline.
Deploy Flexibly
Air-Gapped and Hybrid Ready: Deploy your Fabric on-prem, in your VPC, or at the edge to meet strict compliance and feed a consolidated data lake
Air-Gapped and Hybrid Ready: Deploy your Fabric on-prem, in your VPC, or at the edge to meet strict compliance and feed a consolidated data lake
Case Studies
Endless Possibilities for Data Teams
Fleak's OCSF schema intelligence enabled a leading cybersecurity platform to eliminate its two-quarter integration bottleneck, reducing onboarding to one week and unlocking a 4x revenue lift in six months.
Fleak's OCSF schema intelligence enabled a leading cybersecurity platform to eliminate its two-quarter integration bottleneck, reducing onboarding to one week and unlocking a 4x revenue lift in six months.
Fleak's OCSF schema intelligence enabled a leading cybersecurity platform to eliminate its two-quarter integration bottleneck, reducing onboarding to one week and unlocking a 4x revenue lift in six months.
Fleak acts as an In-Motion Data Orchestrator, automatically standardizing streams, enriching them, and routing them reliably to analytics, enabling zero-friction system integration.
Fleak acts as an In-Motion Data Orchestrator, automatically standardizing streams, enriching them, and routing them reliably to analytics, enabling zero-friction system integration.
Fleak acts as an In-Motion Data Orchestrator, automatically standardizing streams, enriching them, and routing them reliably to analytics, enabling zero-friction system integration.

FAQ
Why should we move beyond pipeline tools like Cribl or AWS Glue?
Does Fleak cause vendor lock-in?
Is this just for one-time migrations? What happens when a vendor changes their schema?
Will Fleak replace my Data Engineers?
How does Fleak handle high-volume streams and existing Databricks environments?
How do you guarantee data consistency across complex standards (OCSF, CIM, etc.)?
FAQ
Why should we move beyond pipeline tools like Cribl or AWS Glue?
Does Fleak cause vendor lock-in?
Is this just for one-time migrations? What happens when a vendor changes their schema?
Will Fleak replace my Data Engineers?
How does Fleak handle high-volume streams and existing Databricks environments?
How do you guarantee data consistency across complex standards (OCSF, CIM, etc.)?
FAQ
Why should we move beyond pipeline tools like Cribl or AWS Glue?
Does Fleak cause vendor lock-in?
Is this just for one-time migrations? What happens when a vendor changes their schema?
Will Fleak replace my Data Engineers?
How does Fleak handle high-volume streams and existing Databricks environments?
How do you guarantee data consistency across complex standards (OCSF, CIM, etc.)?
Data Team Approved
As AI workflows and applications scale, complexity becomes a bottleneck. Fleak allows teams to collaboratively design, build, and deploy efficiently, ensuring seamless scalability and streamlined infrastructure management for growing businesses.

Fred Bliss
Applied AI & Innovation
The advanced features of Fleak have enhanced our data processing with low latency times. It's a tool worth trying for any data professional.

Alan Li
Product Manager, Meta
Handling high traffic is no longer a concern with Fleak. Its scalability and reliability make it a solid choice for managing large-scale operations.

Joanna Hu
Applied Science, Amazon
Fleak’s deployment strategy ensures that our updates are smooth and without downtime. It’s a reliable solution for continuous service.

Qianwen Chen
Sr. Principal Architect, Salesforce
Using Fleak has helped us reduce our operational costs. Its serverless architecture allows us to focus on innovation without worrying about infrastructure. Fleak's a valuable addition to our tech stack.

Rajiv Bhat
CEO, Martini.ai
Fleak’s deployment strategy ensures that our updates are smooth and without downtime. It’s a reliable solution for continuous service.
Qianwen Chen
Sr. Principal Architect, Salesforce
Handling high traffic is no longer a concern with Fleak. Its scalability and reliability make it a solid choice for managing large-scale operations.
Joanna Hu
Applied Science, Amazon
The advanced features of Fleak have enhanced our data processing with low latency times. It's a tool worth trying for any data professional.
Alan Li
Product Manager, Meta
As AI workflows and applications scale, complexity becomes a bottleneck. Fleak allows teams to collaboratively design, build, and deploy efficiently, ensuring seamless scalability and streamlined infrastructure management for growing businesses.
Fred Bliss
Applied AI & Innovation
Start Building with Fleak Today
Lakehouse Ready Data in Minutes
Start Building with Fleak Today
Lakehouse Ready Data in Minutes