Imagine this: It’s Monday morning, and you’re about to step into a critical team meeting.

By
Bo Lei
Co-Founder & CTO, Fleak

Over the weekend, your Slack channel has been buzzing with discussions, and now you need a concise summary of the key points. Manually going through hours of team conversations is neither practical nor efficient.
At Fleak, we’ve encountered this exact challenge, particularly in enterprise environments where timely retrieval of information is crucial. While many communication platforms offer built-in AI tools to search and analyze chat history, the example we’re discussing here involves calling a chat history data API using an AWS Lambda function. This approach focuses on retrieving chat data, but what sets it apart is the flexibility to customize and scale the solution based on specific organizational needs, making it more adaptable than standard built-in tools.
While this workflow API was designed for internal use, it showcases the transformative potential of combining serverless computing with AI in any organization. The possibilities extend beyond Slack, opening up a world of applications where timely and accurate information retrieval is crucial.
Understanding Function Calling
Function calling in LLMs represents a significant leap forward in how these models interact with external tools and services. Traditionally, language models have been used primarily for text generation. However, function calling enables LLMs to execute specific tasks, such as fetching data from a database, performing calculations, or accessing APIs, thus expanding their utility far beyond simple text generation.
How Function Calling Works:
Defining Functions: To utilize function calling, you define the necessary functions as the tools parameter when invoking the LLM. This setup includes natural language prompts that guide the model’s responses.
Processing Input: When the model processes a user’s input, it doesn’t just generate a text response. Instead, it evaluates whether there’s a relevant function that can fulfill the request.
Executing Functions: If a suitable function is identified, the model returns the function’s name along with the required parameters. The caller then executes the function based on these parameters.
Returning Results: The function’s result is passed back to the model in a second call, where it is integrated into the final output. This process allows the model to deliver more accurate and contextually relevant answers, especially for tasks requiring dynamic or real-time data.
For instance, if you’re building an application that requires real-time stock data, the LLM can instruct your application to call a specified function with specified parameters to fetch the latest stock prices, ensuring that the information provided is both timely and accurate. For more in-depth information, you can explore the details in OpenAI’s documentation.
Implementing the Slack Agent API in Fleak
To bring our Slack agent API to life, we utilized Fleak’s LLM node as the orchestrator, calling on external LLMs and AWS Lambda functions to deliver the final result.
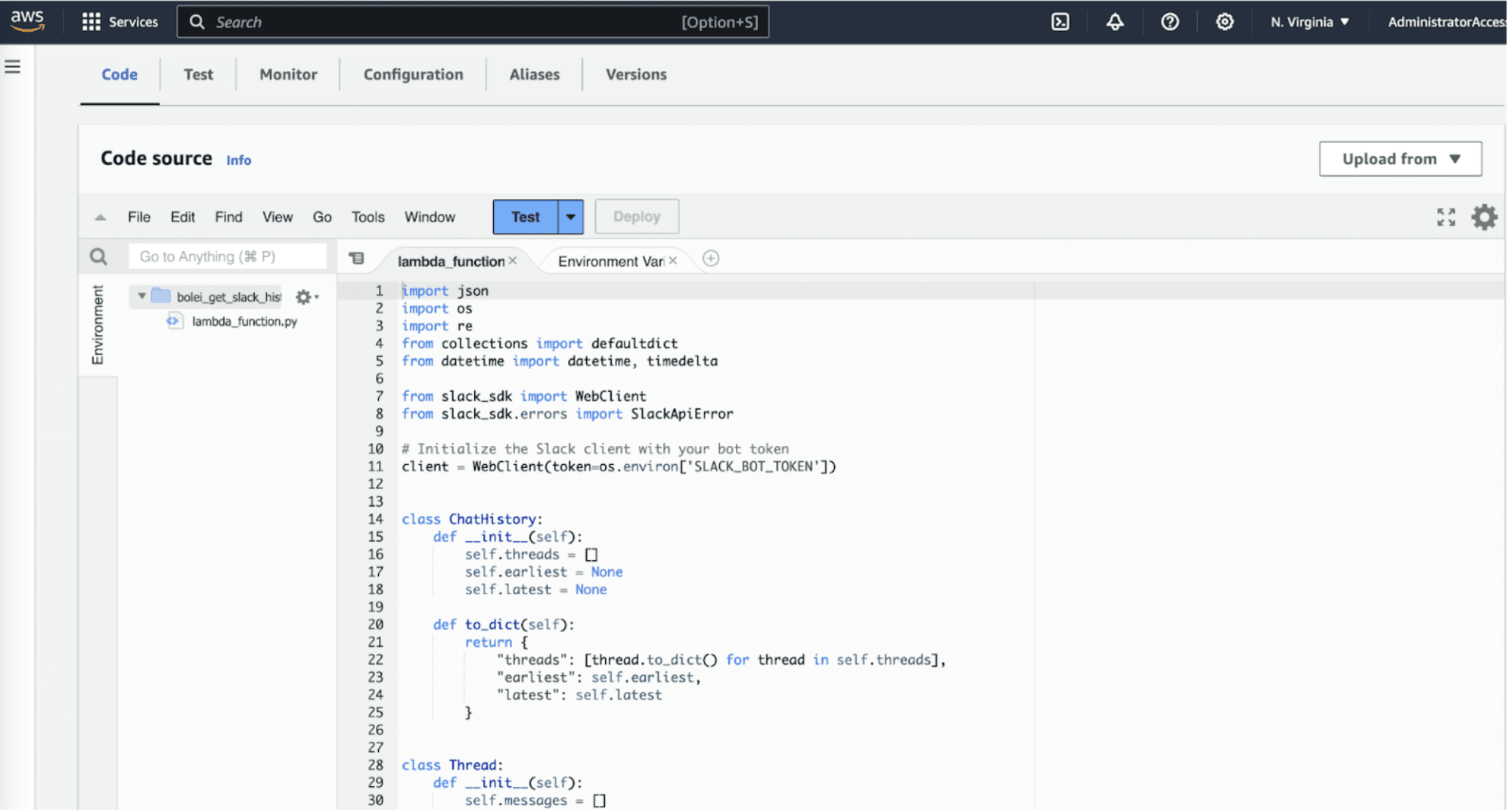
Step 1: Implementing the Lambda Function
The journey begins with implementing a Lambda function designed to fetch Slack chat history. Given a channel ID and a specified look-back period, this function retrieves the conversation history from Slack, forming the data backbone for the entire workflow. The Lambda function is essential as it enables real-time data retrieval, ensuring that the information processed by the LLM is up-to-date and relevant. The code for this function is available in our GitHub repository here.
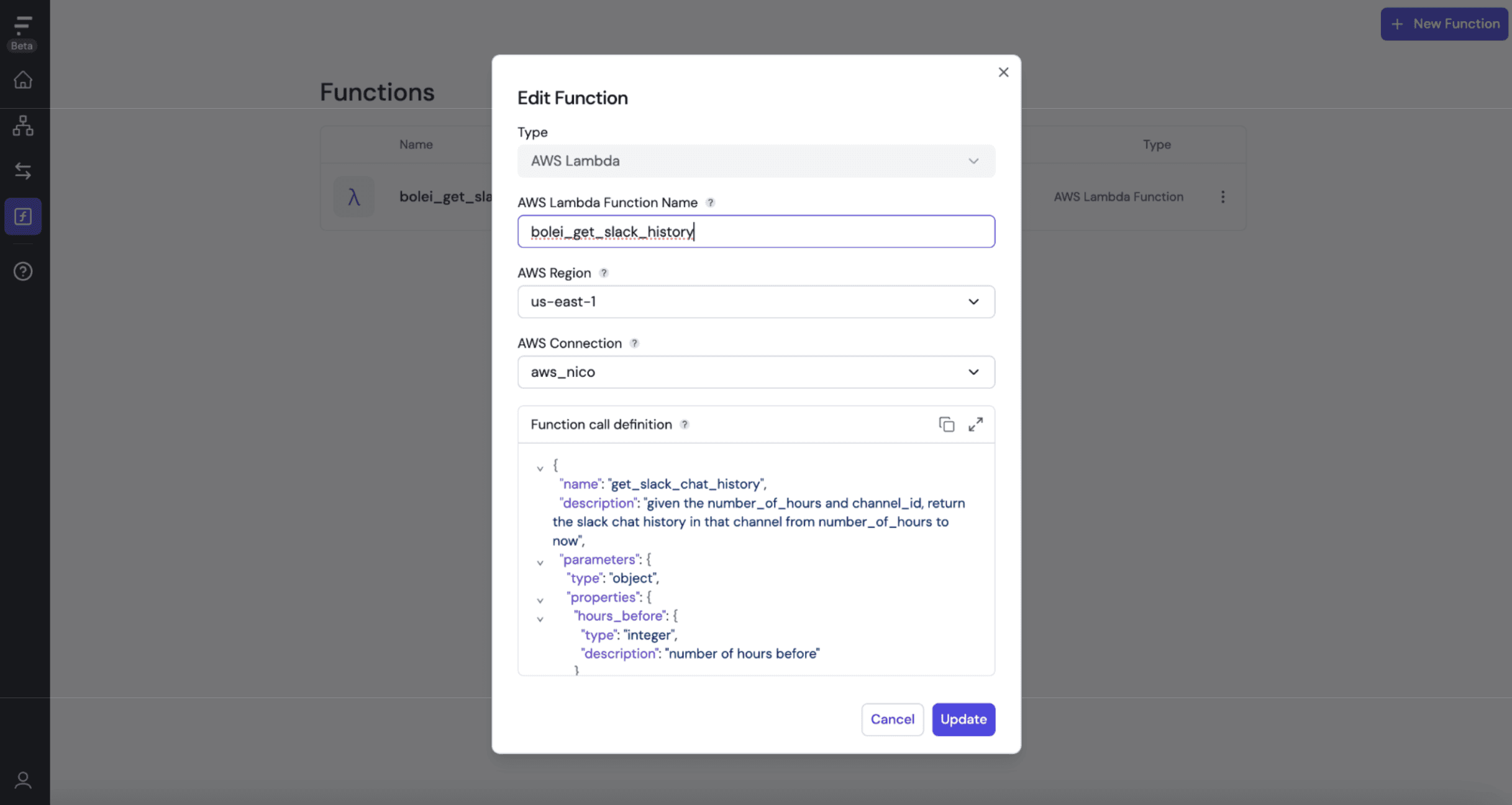
Once the Lambda function is ready, it’s registered in Fleak as a custom function, allowing the LLM Node to invoke it during the workflow. This setup enables seamless integration between the LLM and the Lambda function, facilitating dynamic and automated responses based on real-time data.
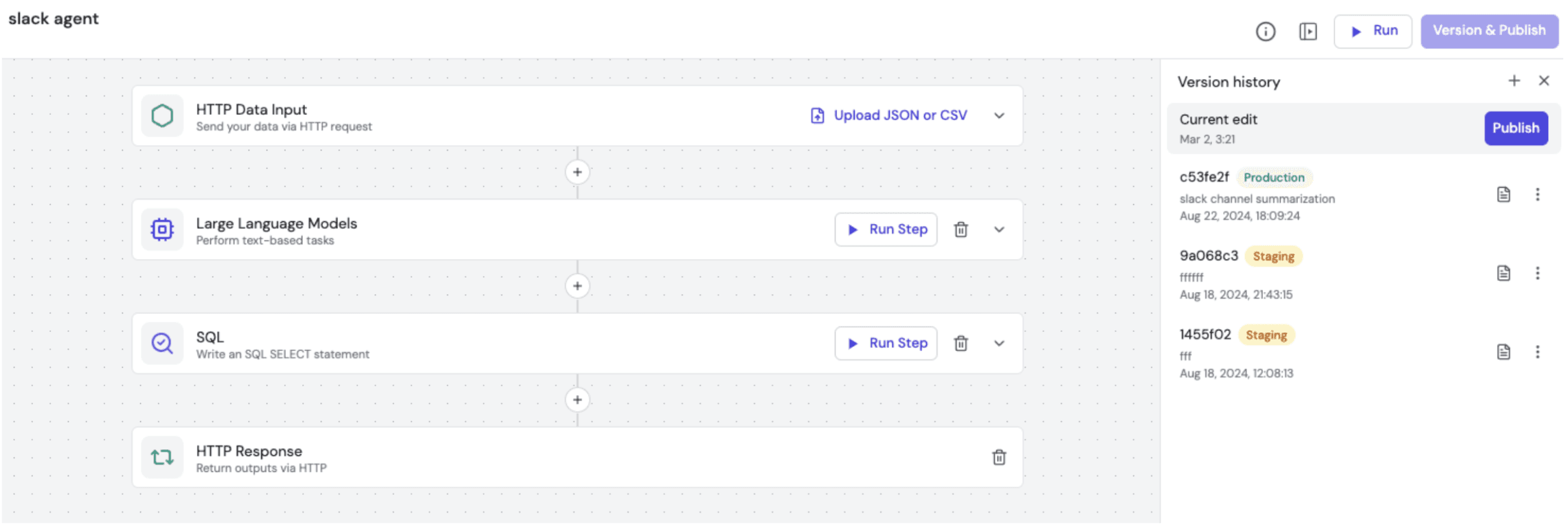
Step 2: Configure the Workflow with Fleak
With the Lambda function in place, the next step is constructing the workflow within Fleak. We start by adding an LLM node, which orchestrates the LLM function call flow. This is configured with GPT-4o, along with appropriate system and user messages. Crucially, we also attach the available functions, including the one we just registered.
Let’s say you submit a query like, “What happened in the Slack channel over the past 24 hours?” to the API. Here’s what happens under the hood:
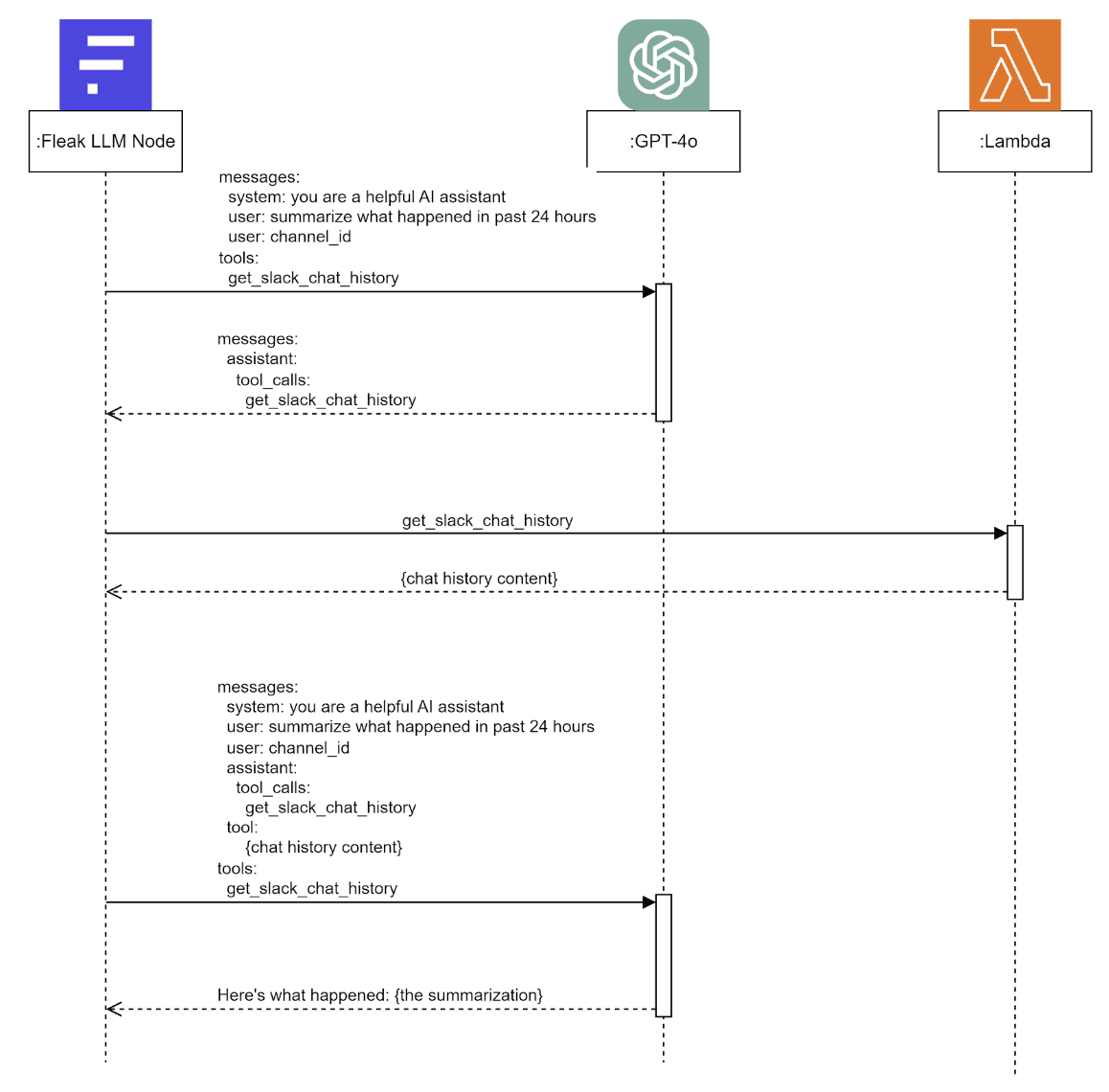
Here’s a breakdown of the process:
Initial Call: When a query like “What happened in the Slack channel over the past 24 hours?” is submitted to the API, the Fleak LLM Node first calls GPT-4. The model determines which function to call (in this case, the Lambda function) and identifies the necessary parameters, such as the channel ID and look-back hours.
Function Execution: The Fleak LLM Node then invokes the Lambda function and retrieves the result—Slack chat history relevant to the specified time frame.
Final Processing: The Fleak LLM Node makes a second call to GPT-4, passing the retrieved chat history along with the function call return. GPT-4 then processes this data to provide a final, context-aware summary based on the function output.
The LLM output is a detailed JSON structure, with the final answer deeply nested.
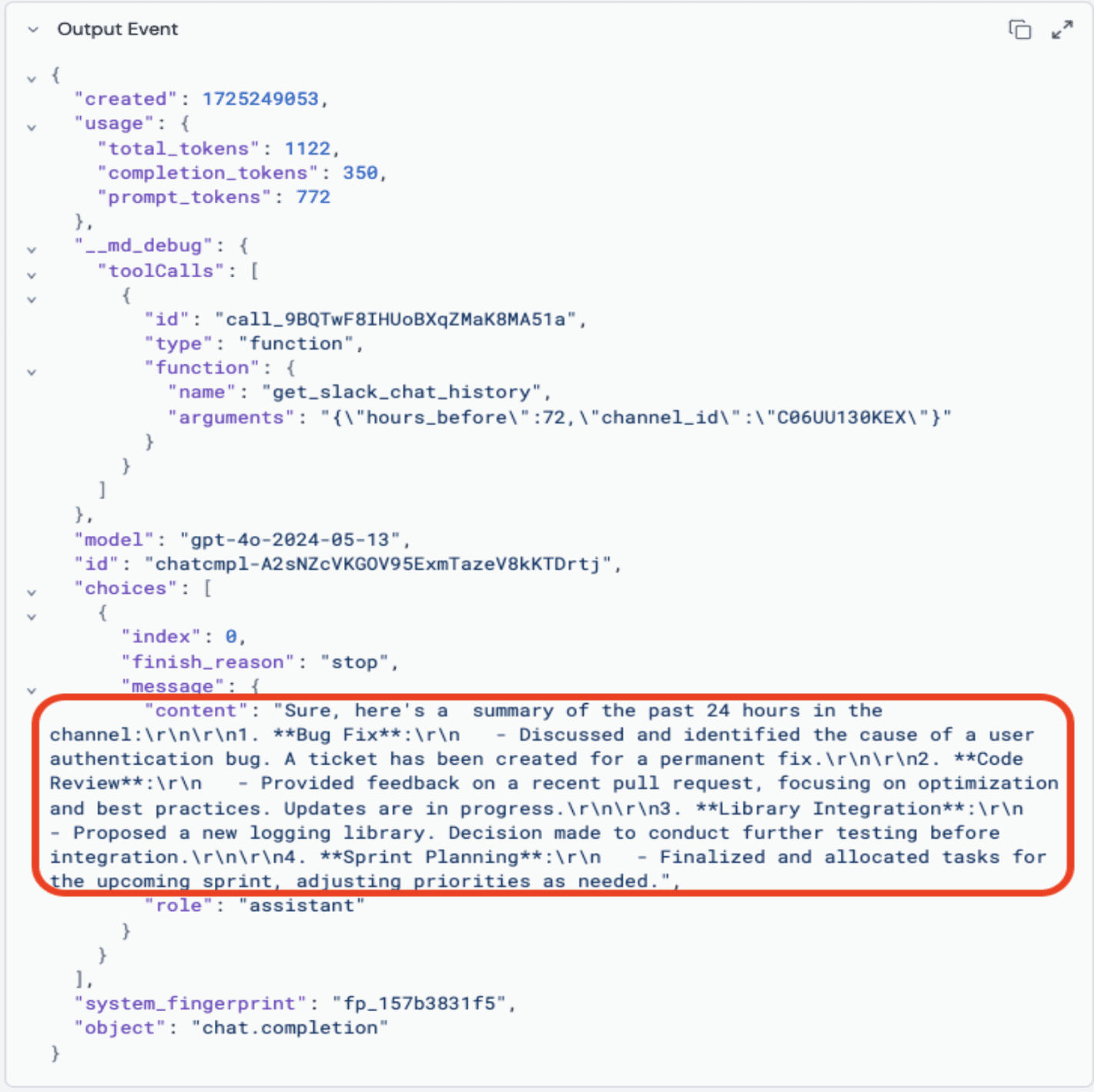
To extract this final output efficiently, we use the Fleak SQL Node. Its SQL capabilities allow us to manipulate this data with ease. For instance, to retrieve the desired answer from the LLM Node’s JSON output, we apply a simple SQL query:
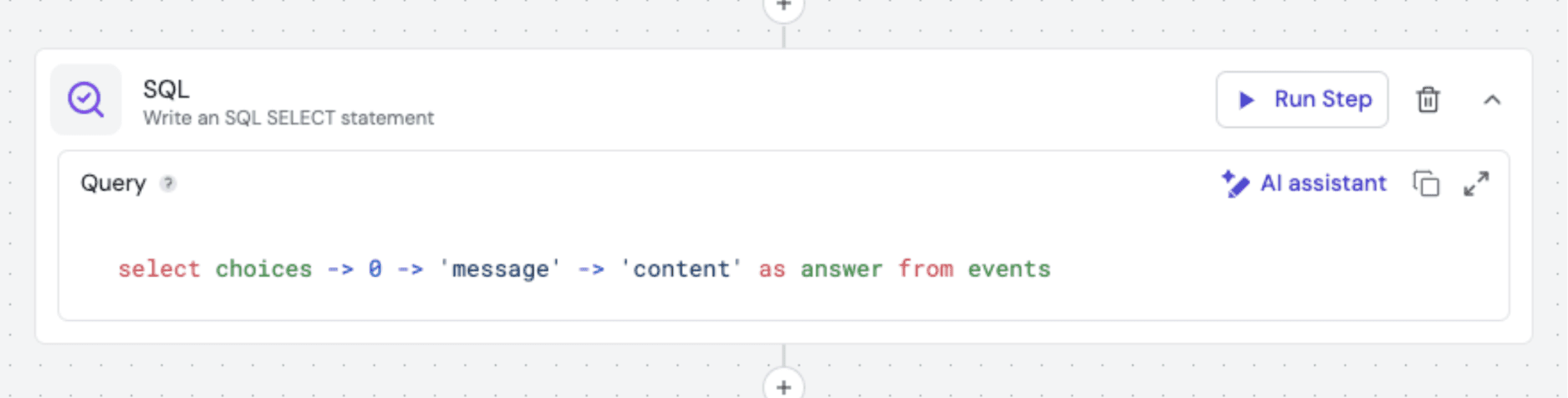
And voilà, we get the final result:

Step 3: Publishing the Workflow as an API
With the workflow ready, publishing it as an API is incredibly straightforward in Fleak—just one click, and the entire workflow is deployed as a production-ready API. This API can then be accessed via any HTTP client, allowing seamless integration with your existing applications and services.

Expanding Use Cases
While our primary example focuses on Slack, the principles and techniques described here can be applied to a wide range of scenarios:
Real-Time Data Monitoring: Use function calls to monitor live data feeds, such as stock prices, sensor readings, or social media trends, and provide real-time insights.
Automated Report Generation: Automatically retrieve data from multiple sources, analyze it, and generate comprehensive reports—ideal for business intelligence and analytics.
Dynamic Content Personalization: Fetch user-specific data, such as recent purchases or browsing history, to tailor content or product recommendations in real-time.
These use cases illustrate the flexibility and power of integrating LLM function calls with AWS Lambda, enabling organizations to automate complex workflows and improve decision-making processes.
By leveraging Fleak’s LLM orchestration and AWS Lambda’s serverless power, we’ve developed a robust internal workflow API that streamlines complex data retrieval into an automated, real-time solution. This example not only enhances our internal operations but also demonstrates the potential for integrating AI-driven insights with scalable, cloud-based infrastructure.
Enhancing AWS Lambda Functions with Fleak's API Integration
At Fleak, we make it easy to bring together different tools—whether it’s AWS Lambda, Large Language Models (LLMs), or SQL data transformation—into one seamless workflow. Instead of managing these components separately, Fleak optimizes everything under a single API endpoint, allowing you to build complex data transformations without extensive development cycle or significant operation overhead. You can also check this documentation here to learn how to add an AWS Lambda function from scratch.
And if you're curious about how this example can be customized for your own use cases, feel free to book a demo on Fleak.ai—we’d love to show you how it works!
Other Posts
Jul 2, 2025
The OWASP LLM Top 10 for 2025: A Practical Security Guide for Engineering Teams
The OWASP 2025 LLM Top 10 is here, targeting real-world attacks. Our guide for engineers breaks down new threats like Vector Security and Prompt Leakage, offering practical tips to secure your LLM apps from sophisticated exploits.

Jun 15, 2025
OCSF to S3: Streaming with Kinesis, Firehose, and Zephflow
In Part 2, we build the final stage of our pipeline. Learn to stream OCSF logs to S3 as Parquet using Kinesis Firehose, a Glue schema, and a Zephflow sink, making your data ready for large-scale analysis.
Jun 13, 2025
From VPC Logs to OCSF: A Streaming Pipeline with Kinesis and Zephflow
In part one of our series with Cardinal, learn to transform AWS VPC logs into the query-ready OCSF format. We'll build a streaming data pipeline using Fleak's OCSF Mapper, Zephflow, and Kinesis.
